



我對 GPT-5.5 這次發布的第一個判斷,不是「它到底有多強」,而是另一個更現實的問題:現在的大模型發布,已經不能只看廠商給你的那張表了。
表格不一定是假的,但表格一定是有視角的。OpenAI 會把 GPT-5.5 最強的地方放在最顯眼的位置,Anthropic 會把 Claude Opus 4.7 最穩的地方講得更漂亮,Google 也會把 Gemini 的長上下文與低價優勢包裝成一個舒服的敘事。這些都不是陰謀,這是商業宣傳。問題是,如果我們是用戶、開發者,甚至是要把 AI 接進自己產品的人,就不能只用宣傳頁理解模型。因為真正付錢的人不是發布會,是我們。

這篇文章我會用第一人稱把我自己的判斷寫清楚。不是要把 GPT-5.5 神化,也不是要說它是騙局。
我想拆的是三筆帳:
第一筆,是基準測試的帳。 哪些指標真的代表工作能力,哪些只是漂亮但跟你日常無關。
第二筆,是價格的帳。 API 定價、長上下文、Batch/Flex、訂閱方案,表面價格和實際成本不是同一件事。
第三筆,是信任的帳。 模型越強,不代表越老實。能力變強,有時候只是讓它把錯話講得更像真的。
GPT-5.5 到底強在哪裡
GPT-5.5 當然是一次明顯升級。
如果只看 OpenAI 自己公布的資料,它在 Terminal-Bench 2.0 上拿到 82.7%,比 GPT-5.4 的 75.1% 高,也高於 Claude Opus 4.7 的 69.4% 和 Gemini 3.1 Pro 的 68.5%。
這個指標很重要,因為 Terminal-Bench 不是單純問答,而是把 AI 放進命令列環境,讓它操作檔案、跑工具、寫程式、修問題。這更接近現在 AI 編程代理的真實工作方式。
但如果因此得出「GPT-5.5 全面碾壓」這個結論,就太粗糙了。
同一份 OpenAI 發布資料裡,SWE-Bench Pro 的數字是 GPT-5.5 58.6%,Claude Opus 4.7 是 64.3%。也就是說,到了真實程式庫修 bug、解 issue 的場景,Claude 反而有公開數字上的優勢。
GPT-5.5 確實很強,尤其強在代理式編程與長任務執行,但它不是所有任務的唯一答案。

這也是我現在看模型發布時最在意的地方:不要只看誰在一張榜上第一名,要看那張榜到底在測什麼。
同樣叫「編程能力」,裡面可以拆成很多種截然不同的東西:看得懂需求、在大型 codebase 裡定位問題、改完後自己跑測試、理解錯誤訊息、不破壞既有架構、上下文很長時不失憶,以及——最容易被忽略的——知道自己不知道什麼。這些東西不會被一個分數完整代表。
我以前做逆向工程、做基礎設施、做 Token 中轉站,越往深處走越清楚一件事:真正有價值的比較,永遠不是單點比較,而是場景比較。 命令列任務很強,不代表引用型文章最可靠;數學題很強,不代表適合客服;上下文很長,不代表真的會把 300K token 裡的重要訊息用對。模型不是神明,是工具。工具要放回場景裡才有意義。
八個指標,我會這樣看
我會把 GPT-5.5 和其他模型放在八個維度裡看,這個框架本身有用,但我不想把它當排行榜看,更想把它當任務分類看。
Terminal-Bench 2.0 看的是終端環境裡的實作能力。這對程序員、DevOps、AI coding agent 很重要。GPT-5.5 的 82.7% 是很強的訊號,代表它確實更會在工具環境裡完成工作。
GDPval 看的是知識工作,OpenAI 說它涵蓋 44 種職業。GPT-5.5 是 84.9%,GPT-5.4 是 83.0%,Claude Opus 4.7 是 80.3%。這裡的差距沒有 Terminal-Bench 那麼大,代表在普通知識工作裡,幾個前沿模型已經接近一個平台期。
OSWorld-Verified 看的是電腦操作能力。GPT-5.5 是 78.7%,Claude Opus 4.7 是 78.0%。這種差距,我不會說誰壓倒誰,因為真實電腦操作很吃工具接入、權限、UI 環境和任務設計。
Toolathlon / MCP Atlas / Tau2-bench 這類是工具調用與代理流程能力。這裡最值得注意的不是分數高低,而是「工具調用仍然是 AI 很容易翻車的地方」。模型自己會說會做,和它真的能穩定地用 API、讀返回值、處理異常,是兩件事。
BrowseComp 看的是多網頁瀏覽與資訊抽取。這類任務現在幾個大模型都已經很強,差距不像早期那麼明顯。真正的差別往往不是「會不會查」,而是「查完會不會亂總結」。
FrontierMath Tier 1-3 / Tier 4 看的是高階數學能力。這個對模型研究很重要,但對大多數電商、客服、OCR、社群工具、內容生成應用來說,並不是第一優先級。
CyberGym / CTF 類指標 看的是資安能力。這類能力很敏感,因為它同時可以用來防禦,也可以用來攻擊。OpenAI 在 GPT-5.5 發布文裡也特別提到更嚴格的 cyber safeguards,這代表模型能力上去了,平台也會更積極地限制高風險使用。
SWE-Bench Pro 我會特別補回來。因為對 AI 編程來說,這是非常關鍵的指標:讓模型在真實 repo 裡解真實 issue。這比「寫一段演算法範例」更接近工程實戰。
簡單說,GPT-5.5 更像一個能接活的代理,而不是一個只會聊天的模型。但這不代表每件事都應該直接上它。
價格:真正的成本不在第一行
說完性能,來看價格,這才是大多數人真正卡住的地方。
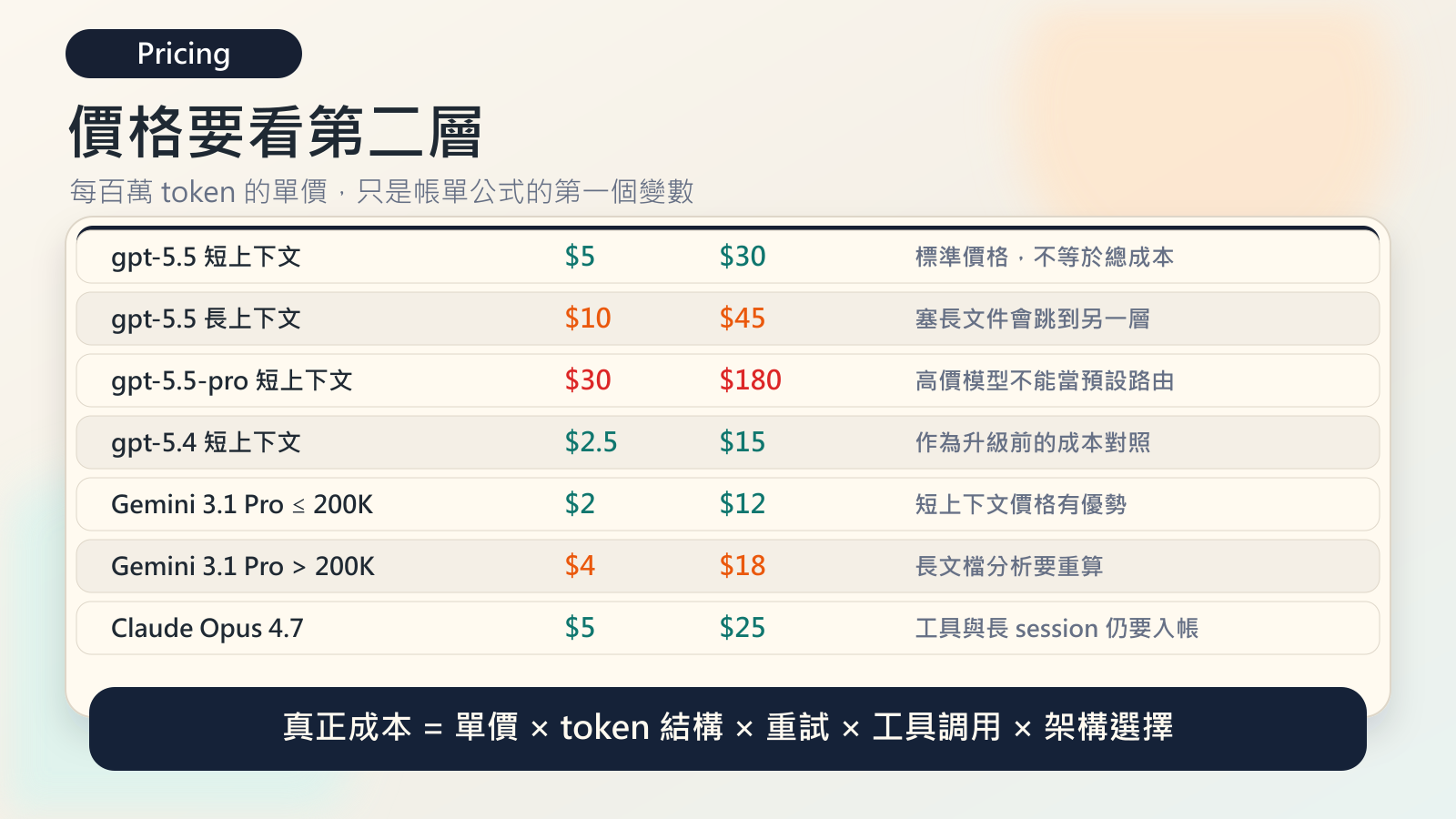
GPT-5.5 的 API 標準短上下文定價:
| 模型 | Input | Cached input | Output |
|---|---|---|---|
| gpt-5.5 | $5 / 1M tokens | $0.5 / 1M tokens | $30 / 1M tokens |
| gpt-5.4 | $2.5 / 1M tokens | $0.25 / 1M tokens | $15 / 1M tokens |
| gpt-5.5-pro | $30 / 1M tokens | - | $180 / 1M tokens |
光看這張表,GPT-5.5 就是 GPT-5.4 的兩倍,但事情沒有那麼簡單。
OpenAI 自己也說 GPT-5.5 比 GPT-5.4 更 token efficient,也就是完成同樣 Codex 任務時通常會用更少 token。Artificial Analysis 也提到,在他們的 Intelligence Index 測試裡,per-token 定價雖然翻倍,但 token 使用量大約少了 40%,所以實際跑那組測試的成本增加接近 20%,不是直接翻倍。
不過這個數字不太建議直接套用在自己的業務上,因為 Artificial Analysis 測的是它們那套任務,不是你的產品流量。
如果你的場景是長文生成、客服多輪對話、用戶亂問、工具反覆調用、代碼代理不斷跑測試,實際 token 結構可能完全不同。
價格還有幾個容易被忽略的地方。
第一,長上下文可能跳價。
OpenAI pricing 頁裡,gpt-5.5 有 short context 和 long context 兩個價格欄。短上下文是 $5 / $30,長上下文則是 $10 / $45。gpt-5.5-pro 長上下文更高,input 到 $60,output 到 $270。
所以你不能只看第一行價格。只要你的產品開始塞長文件、整個 repo、PDF、會議紀錄、聊天歷史,價格就會進入另一層。
第二,Batch / Flex 會讓價格變另一個世界。
OpenAI 的 Batch 和 Flex 對 gpt-5.5 是標準價格的一半。Google Gemini 也是 Batch/Flex 半價。這代表如果你的任務不是即時互動,而是報表生成、批量摘要、離線分析、資料抽取,那你應該優先想架構,而不是先想換模型。
能非同步的工作硬跑即時 API,就是在燒錢。
第三,Gemini 的便宜有 200K 分界線。
Google 官方 Gemini API pricing 裡,Gemini 3.1 Pro Preview 在標準 tier 下,小於等於 200K prompt 是 input $2、output $12;超過 200K 之後變成 input $4、output $18。
這就是我最在意的地方:長文檔分析不是免費紅利,而是會進入另一個價格層。
Gemini 在短上下文裡確實很有價格優勢,但如果你是拿它做大型文檔、超長 RAG、整個知識庫壓進去,那就要很小心 200K 這條線。
第四,Claude Opus 4.7 看起來價格穩,但工具與用量結構仍然要算。
Anthropic 官方 pricing 顯示 Claude Opus 4.7 是 input $5、output $25,Batch 是 $2.5 / $12.5,1M context 也在標準 pricing 裡。這張表很好看,但如果你大量用 web search、computer use、text editor tool、長 session、prompt caching,帳單仍然不是單純 input/output 兩列能看完。
我沒有在官方定價頁查到「tokenizer 讓同樣內容多 35% 到 40% token」這個說法有足夠穩的公開依據,所以這篇不把它寫成官方事實。真正要做成本比較,最準的方式不是引用別人的比例,而是用各家的 token counting 或實際 billing,把你自己的任務跑一遍。
看 API 成本,最核心的問題不是每百萬 token 多少錢,而是完成一次你自己的真實任務到底花了多少。
訂閱比 API 便宜,但它們不是同一種東西
我認同一個很實用的判斷:如果你只是自己每天用 AI 寫程式,直接用 ChatGPT Plus、Pro 或 Codex,很多時候會比 API 划算。
這個判斷大方向是對的。
OpenAI 目前 ChatGPT Plus 是 $20/月,Pro 有 $100 和 $200 兩個層級。官方說 Pro $100 是 Plus 的 5 倍用量,Pro $200 是 Plus 的 20 倍用量。Plus 可以用 GPT-5.5 Thinking,Pro 可以用 GPT-5.5 Pro。
如果你是個人開發者,每天大量丟 Codex 任務,訂閱制很可能比自己拿 API 一次次打便宜。
但訂閱制有一個邊界:它是給你用,不是給你的產品用。
你不能把自己的 ChatGPT Pro 帳號拿去當下游服務的後端。OpenAI Help Center 也明確寫到,不允許分享帳號、轉售 access,或用 ChatGPT 去支撐第三方服務。
所以這裡要分清楚:
| 場景 | 比較合理的選擇 |
|---|---|
| 自己寫程式、查資料、做文章 | Plus / Pro / Codex 訂閱 |
| 做內部工具,少量人使用 | 先試訂閱與 API 混合,算清楚用量 |
| 做公開產品、客服、SaaS | API、路由、限流、計費與監控 |
| 大量離線處理 | Batch / Flex / 小模型分流 |
我不喜歡把所有問題都收斂成「買哪個方案」。真正成熟的做法是:個人工作流用訂閱,產品化流量用 API,批量工作用 Batch,低風險任務用便宜模型。
這才是成本結構,而不是省錢小技巧。
最可怕的不是貴,是模型會把錯話講得很像真的
我最想強調的一點,是模型越聰明,不一定越可靠。
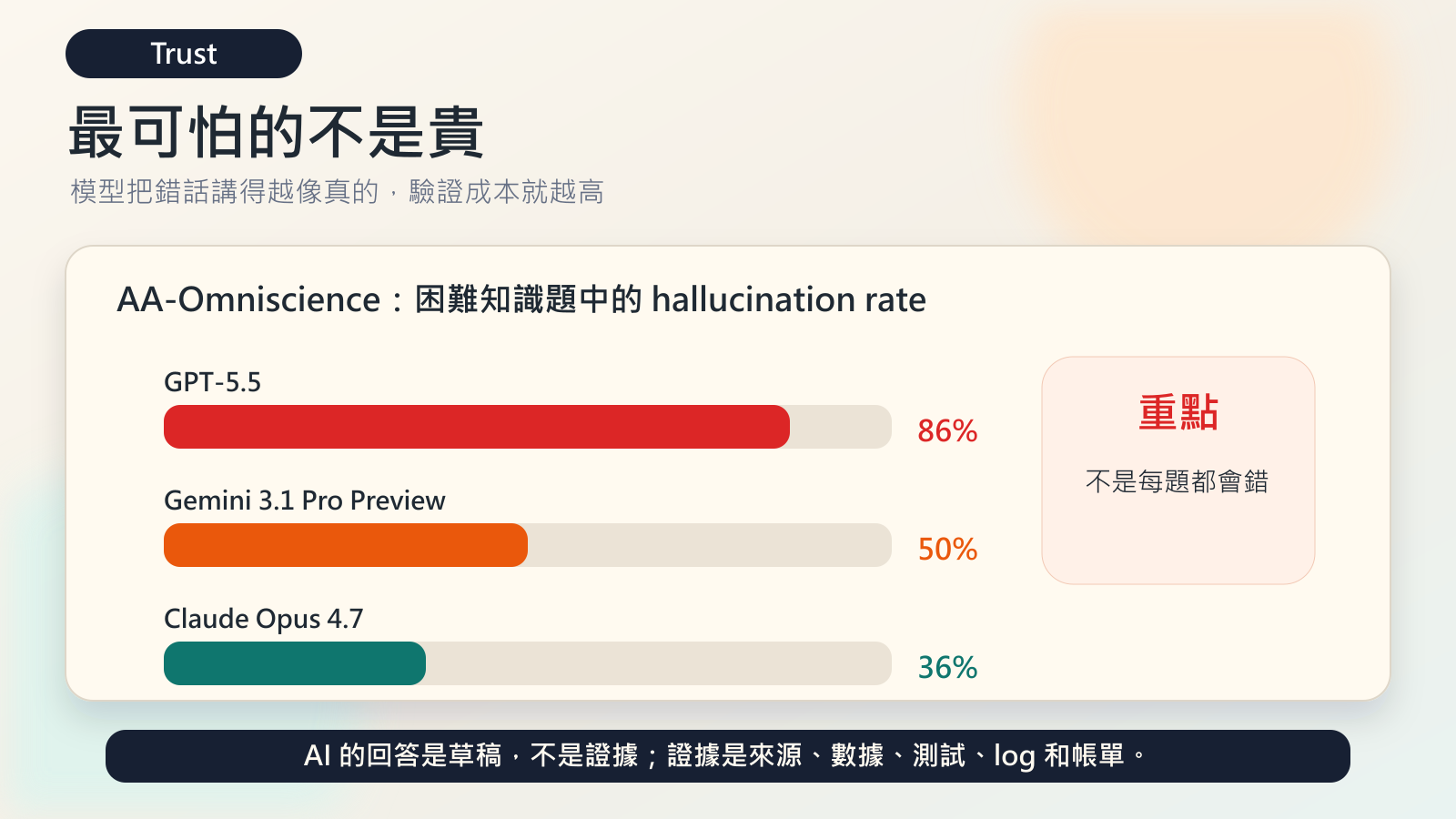
Artificial Analysis 的 GPT-5.5 測試裡提到,GPT-5.5 在 AA-Omniscience 上有最高的 accuracy,達到 57%,但 hallucination rate 是 86%。同一段資料裡,Claude Opus 4.7 是 36%,Gemini 3.1 Pro Preview 是 50%。
這個數字很嚇人,但也要講清楚:它不是說 GPT-5.5 在任何任務裡都有 86% 會胡說。
AA-Omniscience 測的是困難知識題,而且它特別懲罰模型在不知道時亂猜。也就是說,這個 86% 更精確的意思是:在這組困難知識問題中,當 GPT-5.5 沒有足夠知識時,它很容易選擇硬答,而不是承認不知道。
這對普通閒聊可能還好,但對法務文件、醫療建議、投資分析、引用型文章、學術摘要、資安報告、商業合約這類需要可追溯來源的場景,就很危險了。
越強的模型,越容易讓人放下戒心。以前模型胡說,你一眼就看得出來。現在模型胡說,語氣穩定、結構完整、引用看起來像真的,甚至會主動補一段很合理的推論——這才是真正危險的地方。
我現在對 AI 的態度很簡單:AI 的回答是草稿,不是證據。
證據是來源、數據、可復現流程、測試結果、帳單紀錄、commit diff、真實 log。
模型可以幫我整理,但不能替我負責。這也是為什麼我不會把所有流傳數字直接照搬。公開資料和二手整理都可能有簡化或錯位,如果我要寫成自己的文章,就必須把它重新過一遍事實篩子,否則只是把別人的二手敘事包裝成自己的觀點,那不叫實事求是。
我會怎麼選模型
落到實際使用建議,我不會說「大家都用 GPT-5.5」,因為這句話對決策沒有任何幫助。任務不同,模型的優先順序完全不同。

如果是代理式編程,GPT-5.5 值得試。
Terminal-Bench 2.0 的 82.7% 是很強的訊號,尤其是你在用 Codex、需要它讀 repo、改檔案、跑測試、理解錯誤訊息,GPT-5.5 的能力提升會很明顯。
但如果你做的是大型真實 repo 的 issue 修復,我也會把 Claude Opus 4.7 放進比較池,因為 SWE-Bench Pro 的公開數字對 Claude 更有利。
最終答案不是看榜,而是拿你的 codebase 跑一組自己的測試。
如果是引用型研究,我會更保守。
我不會因為 GPT-5.5 更聰明就讓它直接寫最終結論。這類任務我一定會要求來源、日期、引用、交叉驗證,必要時用瀏覽工具查一遍原文。
如果模型沒有來源,我就把它當靈感,不當事實。
如果是長文檔分析,我會先做壓縮與檢索。
不要把「上下文很長」理解成「可以把所有東西都塞進去」。這是很多人燒 token 的起點。
長上下文有三個問題:貴、慢,還有模型不一定真的抓到重點。
我的做法會是先切分、摘要、檢索、分層,再把真正需要推理的部分交給高階模型。不是所有 token 都值得進最貴的模型。
如果是高流量 API 產品,我一定做模型路由。
簡單分類、格式轉換、摘要、客服第一輪,不需要每次都上 GPT-5.5 或 Opus 4.7。
高階模型應該用在「低頻高價值」任務,而不是拿來處理所有雜訊。
這不是節省一點小錢,而是產品能不能長期活下去。
這次 GPT-5.5 真正提醒我的事
GPT-5.5 的發布,表面上是一個模型升級。
但我看到的是另一件事:AI 的競爭正在從模型能力,走向整套使用權力的競爭。
誰的上下文更長、工具生態更完整、能把高階模型包進訂閱讓一般用戶用得起、能在 Batch/Flex 上降低批量任務成本,還有誰能把模型深度嵌進你的 IDE、文件、瀏覽器和日常工作流——這些才是接下來真正的戰場。
模型本身當然重要,但模型只是其中一層。真正決定你能不能用得起、用得穩、用得對的,是價格、配額、工具、生態、限制、合規,以及你自己的判斷力。
這和我之前寫 Token 中轉站、算力成本、隱性知識時的判斷是同一件事:
真正重要的東西,往往不在表面。
用戶看到的是模型名稱,開發者看到的是 API 價格,真正做產品的人看到的是帳單、延遲、失敗率、重試、上下文膨脹、工具錯誤、資料來源、合規風險和用戶濫用。這些東西,OpenAI 不會替你算,Anthropic 不會,Google 也不會。廠商只會告訴你模型更強、更快、更便宜、更適合工作,但最後真正要回答的問題,是你自己:
這個模型在你的任務裡真的更好嗎?省下來的時間有沒有被驗證成本吃回去?那行便宜的單價,有沒有被長上下文和反覆重試放大?最後,它給你的答案,你有沒有能力判斷真假?如果這些問題還沒想清楚,那換模型只是在追發布節奏,不是在用 AI 解決問題。
我的最後判斷
GPT-5.5 我會用。
尤其是編程、長任務代理、複雜資料整理、需要模型自己用工具往下推進的場景,我會把它放進主力測試池。
但我不會無腦把所有任務都切到 GPT-5.5。
我會保留 Claude Opus 4.7 作為嚴肅編程與保守回答場景的對照組,也會保留 Gemini 3.1 Pro 或 Flash 系列處理長上下文與成本敏感任務。
我的模型策略會越來越像基礎設施策略:高價模型只處理高價值問題,長上下文先壓縮再推理,批量任務盡量非同步,需要事實的輸出一定要有來源,不能驗證的答案不能進生產,每次模型升級都要跑自己的基準測試。
以前大家問 AI:「你能不能回答我?」現在更值得問的是:這個答案的成本是多少、風險是多少、我要怎麼驗證它。GPT-5.5 不是終點,它只是把這些問題更清楚地推到了我們面前。
資料來源




